Deadlocks can kill an application’s performance. Users will complain about the app being slow or broken. Developers will ask the DBA to fix the problem, DBAs will push the problem back on developers. The next thing you know, the office looks like Lord of the Flies.
What is a Deadlock?
A deadlock occurs when two queries need exclusive access to different tables and each query is waiting for the other to finish. Assume that there are two tables, tA and tB. There are also two queries, Q1 and Q2. The first query, Q1, takes an exclusive lock on tA at the same time that the second query, Q2, takes an exclusive lock on tB. So far, there’s nothing out of the ordinary happening. Q1 then requests exclusive access to tB. At this point we have a block. Q1 must wait for Q2 to release its lock before Q1 can finish. Q2 now requests an exclusive lock on tA. And here we have a deadlock.
Q1 won’t release its lock on tA until it can get a lock on tB. Q2 won’t release its lock on tB until it can get a lock on tA. In order for either query to finish, they need access to the other query’s resources. That’s just not going to happen. This is a deadlock.
In order for the database to keep responding, one of these queries has to go. The query that’s eliminated is called the deadlock victim.
Finding Deadlocks
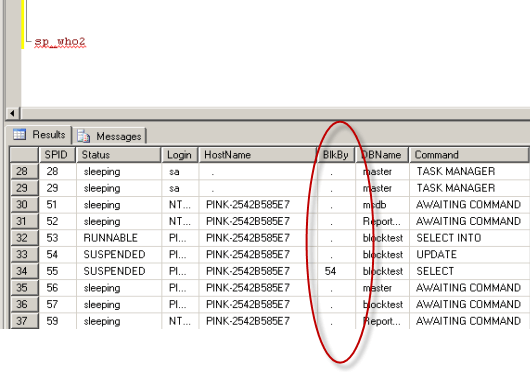
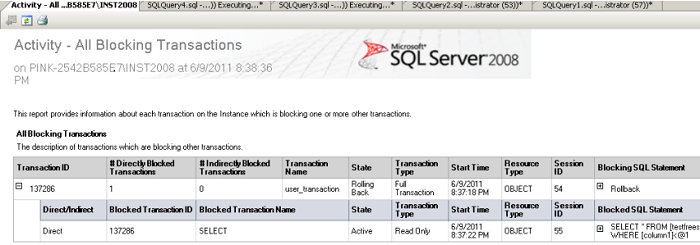
What is the first sign of a deadlock? Queries that should be fast start taking a long time to respond. That’s the first sign of a deadlock, but that’s also the first sign of a lot of other problems. Another sign of a deadlock is an error (error 1205 to be precise) and a very helpful error message: Transaction (Process ID %d) was deadlocked on {%Z} resources with another process and has been chosen as the deadlock victim. Rerun the transaction.
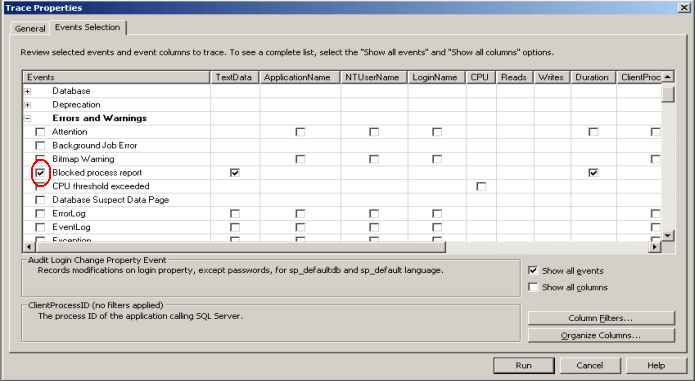
SQL Server is telling you exactly how to solve the problem – re-run your transaction. Unfortunately, if the cause of the deadlock is still running, odds are that your transaction will fail. You can enable several trace flags to detect deadlocks (trace flag2 1204 and 1222), but they output the deadlock to the SQL Server error log and produce output that is difficult to read and analyze.
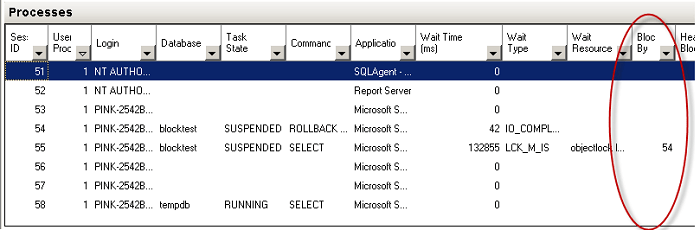
Once deadlocks show up, your database administrator might reach for a script to pull deadlocks out of Extended Events. Extended Events are a great source of data for analysis. Although they’re a relatively new feature to SQL Server, they first appeared in SQL Server 2008, Extended Events already provide an incredibly rich set of tools for monitoring SQL Server. Event data can be held in memory (which is the default) or written out to a file. It’s possible that to build a set of monitoring tools that log all deadlocks to a file and then analyze that file after the events happen.
Yesterday's deadlocks are tomorrow's news!
Just like newspapers help us find out what happened yesterday, Extended Events provide a great way to investigate deadlocks that have already occurred. If you don’t have any other monitoring tools in place, Extended Events are a great place to start. Once you start seeing deadlocks, you’ll want to start gathering more information about them. It takes some skill to read the XML from a deadlock graph, but it contains a great deal of information about what happened. You can find out which tables and queries where involved the deadlock process, which process was killed off, and which locks caused the deadlock to occur.
The flip side of the coin is that Extended Events will give you very fine grained information about every deadlock that has already happened. There’s nothing in Extended Events to help you stop deadlocks from happening or even to detect them right when they are happening. Much like a microscope lets you look at a prepared slide in excruciating detail, Extended Events let you look at a single point in time in excruciating detail. You can only find out about things after they happen, not as they happen.
Deadlock Notifications
Wouldn’t be nice if you received notifications of deadlocks as they were happening? Good news! Deadlocks only happen when data is changed; it’s possible to wrap your modification statements inside a template to record any deadlocks that happen. This template takes advantage of some features in SQL Server to allow the deadlock notifications to get sent out asynchronously – the notifications won’t slow down any applications while they interact with SQL Server.
There is a big problem here: every stored procedure that modifies data needs this wrapper. If the wrapper is missed in one place, there won’t be any deadlock information collected from that query. If the wrapper needs to be changed, it has to be changed everywhere. This can be a good thing, of course, because you can target problem queries for reporting or different queries can respond in different ways. Like using Extended Events, this is a very fine grained mechanism for dealing with deadlocks. Action is taken at the level of a single execution of a query and not at the level of our entire application. If we’re going to take care of deadlocks, we want to do it once and fix things across the entire application.
Deadlocks by Design
Both the Extended Events and notification solution are very cunning ways to get information about deadlocks that have already happened. Neither solution helps applications respond to deadlocks as they happen.
Much like a director deciding to fix it in post, monitoring for deadlocks and trying to solve the problem is a reaction to something that should have been done right in the first place. Maybe budget constraints got in the way, maybe the software had to ship by a deadline, maybe there wasn’t expertise on the team to look into these problems. For whatever reason, something made it into production that causes deadlocks. It doesn’t matter what happened, the problem is there; deadlocks are happening.
Error 1205: Catching Deadlocks with Code
Application developers have tool they can use to cope with deadlocks. When SQL Server detects a deadlock and kills of a query, an error is thrown. That error makes its way back up to the software that made the database call. .NET developers can catch the exception and check the Number. (Deadlocks throw an error number of 1205.)
When a deadlock happens, SQL Server will kill off the cheapest transaction. The “cheapest” transaction is the transaction with the lowest cost. It’s getting rid of something that will be easy to run a second time around. Instead of having deadlocks cause problems, developers can easily check the errors that come back from the database server and try again. You can set the deadlock priority; if you don’t have time to fix to the code, you can specify which queries should run at a lower priority.
This is moving the problem up the chain. The users may not see that there is a deadlock, but the application code still needs to deal with it. Things can still be tricky, though. If there’s a long running transaction holding locks and causing deadlocks, no reasonable amount of re-tries will solve the deadlocking problem.
Reacting to Deadlocks with Architecture
The easiest way to eliminate deadlocks is to design the database to avoid deadlocks. It sounds facetious, doesn’t it? Of course the easiest way to avoid deadlocks is to design so they don’t happen!
There are a few architectural patterns to use in an application to avoid deadlocks.
Pattern 1: Using NOLOCK to Stop Deadlocks
NOLOCK for YESOUCH
A common way to stop deadlocks is to use the NOLOCK query hint. NOLOCK users advocate this approach because they believe it does what it says – it eliminates locking.
NOLOCK doesn’t get rid of all locks, just the ones that make your queries return the right results. You see, NOLOCK stops locking during read operations. In effect, it throws the hinted table or index into READ UNCOMMITTED and allows dirty reads to occur. Locks are still necessary for data modification; only one process can update a row at a time.
By using NOLOCK, you’re telling the database that it’s okay to avoid locking for read safety in exchange for still letting deadlocks happen.
Pattern 2: Indexing for Concurrency
In some cases, deadlocks are caused by bookmark lookups on the underlying table. A new index can avoid deadlocks by giving SQL Server an alternate path to the data. There’s no need for the select to read from the clustered index so, in theory, it’s possible to avoid a deadlock in this scenario.
Think about the cost of an index:
* Every time we write to the table, we probably end up writing to every index on the table.
* Every time we update an indexed value, there’s a chance that the index will become fragmented.
* More indexes mean more I/O per write.
* More indexes mean more index maintenance.
To top it off, there’s a good chance that the index that prevents a deadlock may only be used for one query. A good index makes a single query faster. A great index makes many queries faster. It’s always important to weight the performance improvement of a single index against the cost to maintain and index and the storage cost to keep that index around.
Pattern 3: Data Update Order
A simple change to the order of data modifications can fix many deadlocks. This is an easy pattern to say that you’re going to implement. The problem with this pattern is that it’s a very manual process. Making sure that all updates occur in the same order requires that developers or DBAs review all code that access the database both when it’s first written and when any changes are made. It’s not an impossible task, but it will certainly slow down development.
There’s another downside to this approach: in many scenarios, managing update order is simply too complex. Sometimes the correct order isn’t clear. Managing update order is made more difficult because SQL Server’s locking granularity can change from query to query.
In short, carefully controlling update order can work for some queries, but it’s not a wholesale way to fix the problem.
Common Patterns: Common Failures
One of the problems of all three patterns is that they’re all reactionary. Just like the two methods for detecting deadlocks, they get implemented after there is a problem. Users are already upset at this point. There has already been some kind of outage or performance problem that caused the users to complain in the first place. Of course, sometimes you inherit a problem and you don’t have the opportunity to get good design in place. Is there hope?
Whether you’re starting off new design, or combating existing problems, there is a way that you can almost entirely prevent deadlocks from occurring.
Using MVCC to Avoid Deadlocks
MVCC is a shorthand way of saying Multi-Version Concurrency Control. This is a fancy way of hinting at a much broader concept that can be summarized simply: by maintaining copies of the data as it is read, you can avoid locking on reads and move to a world where readers never block writers and writers never block readers.
This probably sounds like a big architectural change, right? Well, not really.
SQL Server 2005 introduced READ COMMITTED SNAPSHOT ISOLATION (RSCI). RCSI uses snapshots for reads, but still maintains much of the same behavior as the READ COMMITTED isolation level. With a relatively quick change (and about a 10 second outage), any database can be modified to make use of RCSI.
When Should You Use RCSI?
If you actually want my opinion on the subject: always. If you’re designing a new application, turn on RCSI from the get go and plan your hardware around living in a world of awesome. TempDB usage will be higher because that’s where SQL Server keeps all of the extra versions. Many DBAs will be worried about additional TempDB utilization, but there are ways to keep TempDB performing well.
The bigger question, of course, is why should I use RCSI?
Use RCSI to Eliminate Locking, Blocking, Deadlocks, Poor Application Performance, and General Shortness of Breath
RCSI may not cure pleurisy, but it’s going to future proof your application. Somewhere down the road, if you’re successful, you’ll have to deal with deadlocks. Turning on RCSI is going to eliminate that concern, or make it so minimal that you’ll be surprised when it finally happens.
A Snapshot of The Future: Looking Past RCSI
RCSI is probably all that most people think they going to need at the start of their architectural thinking. There will be circles and arrows and lines on a whiteboard and someone will say “We need to make sure that the DBAs don’t screw this up.” What they really mean is “Let’s talk to the data guys in a year about how we can make this greased pig go faster.”
Both of these versions can poop and bark.
During the early stages of an application’s life, a lot of activity consists of getting data into the database. Reporting isn’t a big concern because there isn’t a lot of data to report on and a few tricks can be used to make the database keep up with demands. Sooner or later, though, demand will outstrip supply and there will be problems. Someone might notice that long running reports aren’t as accurate as they should be. Numbers are close enough, but they aren’t adding up completely.
Even when you’re using RCSI, versions aren’t held for the duration of a transaction. The different isolation levels correspond to different phenomenon and those phenomenon, under a strict two-phase locking model, correspond to how long locks are held. When using one of the two MVCC implementations (RSCI or snapshots), the isolation levels and their phenomenon correspond to how long versions are kept around.
Using RCSI, or even READ COMMITTED, locks/versions are only held for a single statement. If a query has to read a table multiple times for a report, there’s a chance that there can be minor (or even major) changes to the underlying data during a single transaction. That’s right, even transactions can’t save you and your precious versions.
SNAPSHOT isolation makes it possible to create versions for the duration of a transaction – every time a query reads a row, it’s going to get the same copy of that row, no matter if it reads it after 5 seconds, 5 minutes, or 5 hours. There could be multiple updates going on in the background but the report will still see the same version of the row.
Getting Rid of Deadlocks in Practice
There are manual ways to accomplish eliminate deadlocks, but they require significant effort to design and implement. In many cases deadlocks can be eliminated by implementing either READ COMMITTED SNAPSHOT ISOLATION or SNAPSHOT isolation. Making the choice early in an application’s development, preferably during architectural decisions, can make this change easy, painless, and can be designed into the application from the start, making deadlocks a thing of the past.
Ref: http://www.brentozar.com/archive/2011/07/difficulty-deadlocks/